Don't Compress Your Intelligence
Follow along in the room, or read this later if you missed it. This is the full talk on designing AI systems with high-fidelity data — why you should keep raw inputs, and how to stay efficient without throwing the originals away.
~7 min read · by Siah Labs
Begin the talk →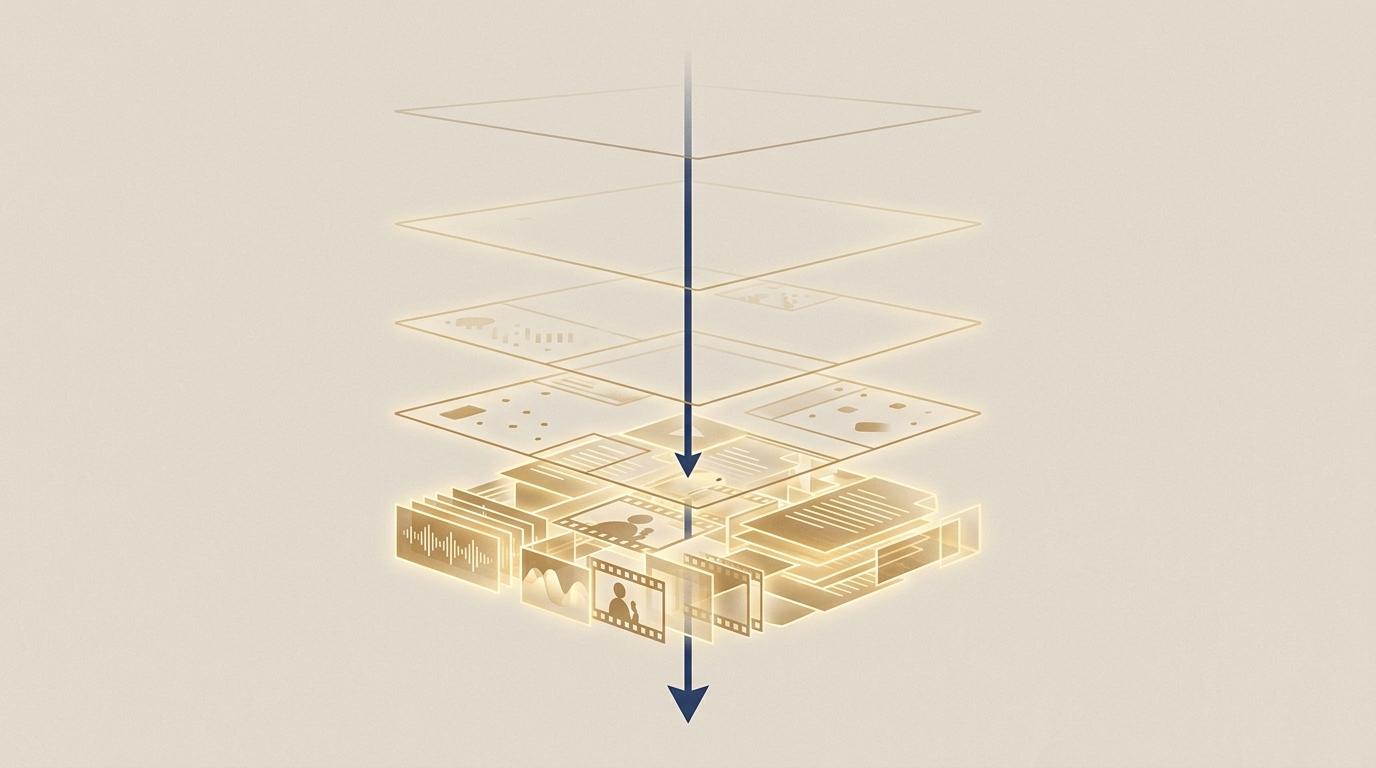
The ladder
Why information loss only runs downhill

Think about a Zoom call. A video recording is richer than audio. Audio is richer than a transcript. A transcript is richer than a summary.
You can always derive the simpler form from the richer one — never the other way around. We get this with Git: we keep the full history of diffs, not just the latest file. Most business systems do the opposite. They save the final decision and throw away the calls, emails, and debates that produced it.
When you compress too early, you are not saving space. You are deleting intelligence your future models will need.
Voice vs. text
Tomorrow’s models need what you capture today

Imagine a voice memo: someone with a deep voice says, "Hi, my name is Emily."
Transcription-only models return the text and stop there. Native audio models can hear the mismatch between the voice and the name — context, not just content.
If your system converted every recording to text and deleted the audio, you would never get that reasoning back. Keep the raw inputs.
What each model type returns for the same clip:
Transcript-only (OpenAI / Claude)
Text wrapper
Hi, my name is Emily.
Correct words — blind to the voice/name mismatch.
Native audio (Gemini)
Native multimodal
The speaker has a deep male voice but introduces themselves as Emily. Possible joke, alias, or recording mismatch.
Listens to the audio, not just the transcript.
Hoard now
The data dictates the use cases — not the other way around
You do not need a finished AI feature to justify collecting high-fidelity data. Start with a simple archive: notes, logs, recordings, whatever your team already produces.
When models improve, new use cases appear on top of the same archive — embeddings, newsletters, summaries you can rerun with better prompts. Hoard now, build later.
API payloads
Compress what you send — not what you store
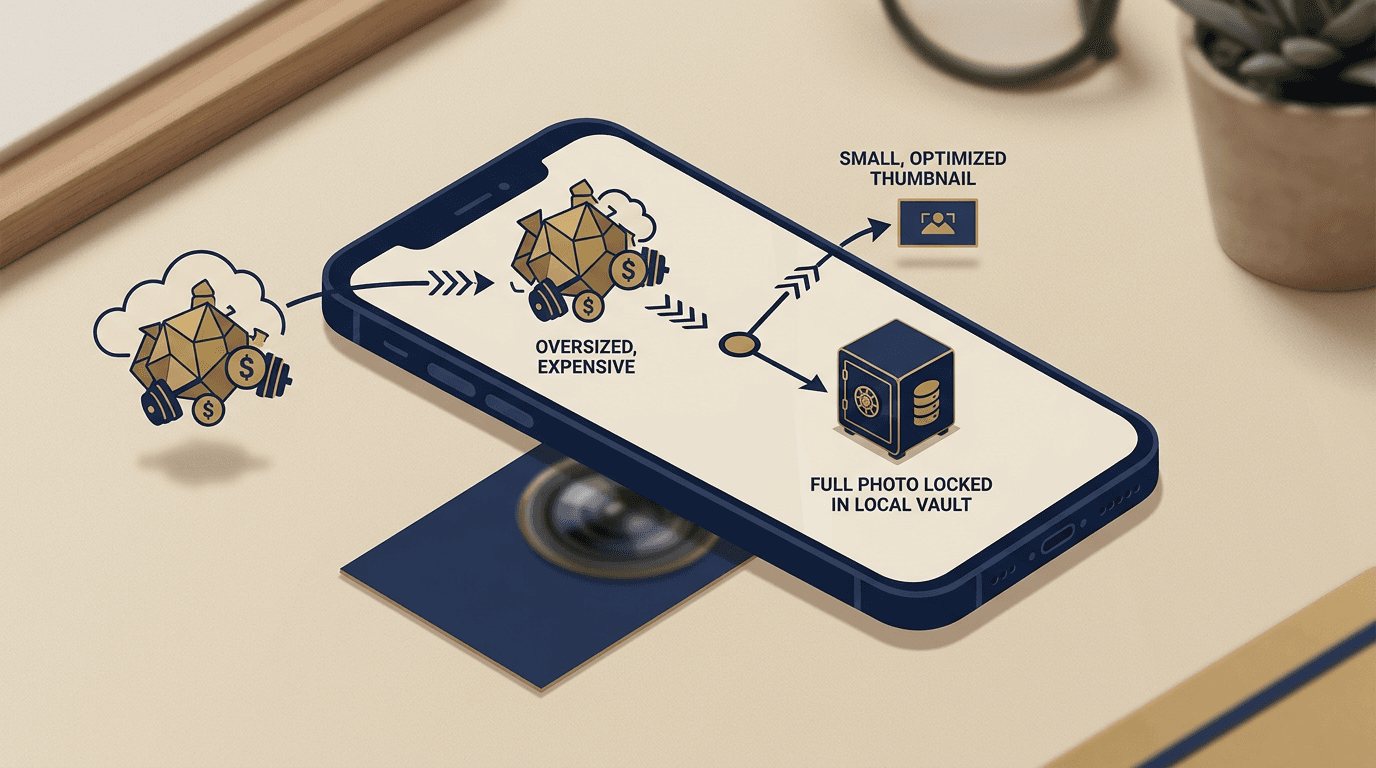
Keeping everything raw does not mean sending everything raw. A business card scanner can resize a 12 MP photo before the API call, cut cost by roughly 25×, and lose zero intelligence — because the original still lives in your database.
Audio costs
Audio APIs bill by length, not file size
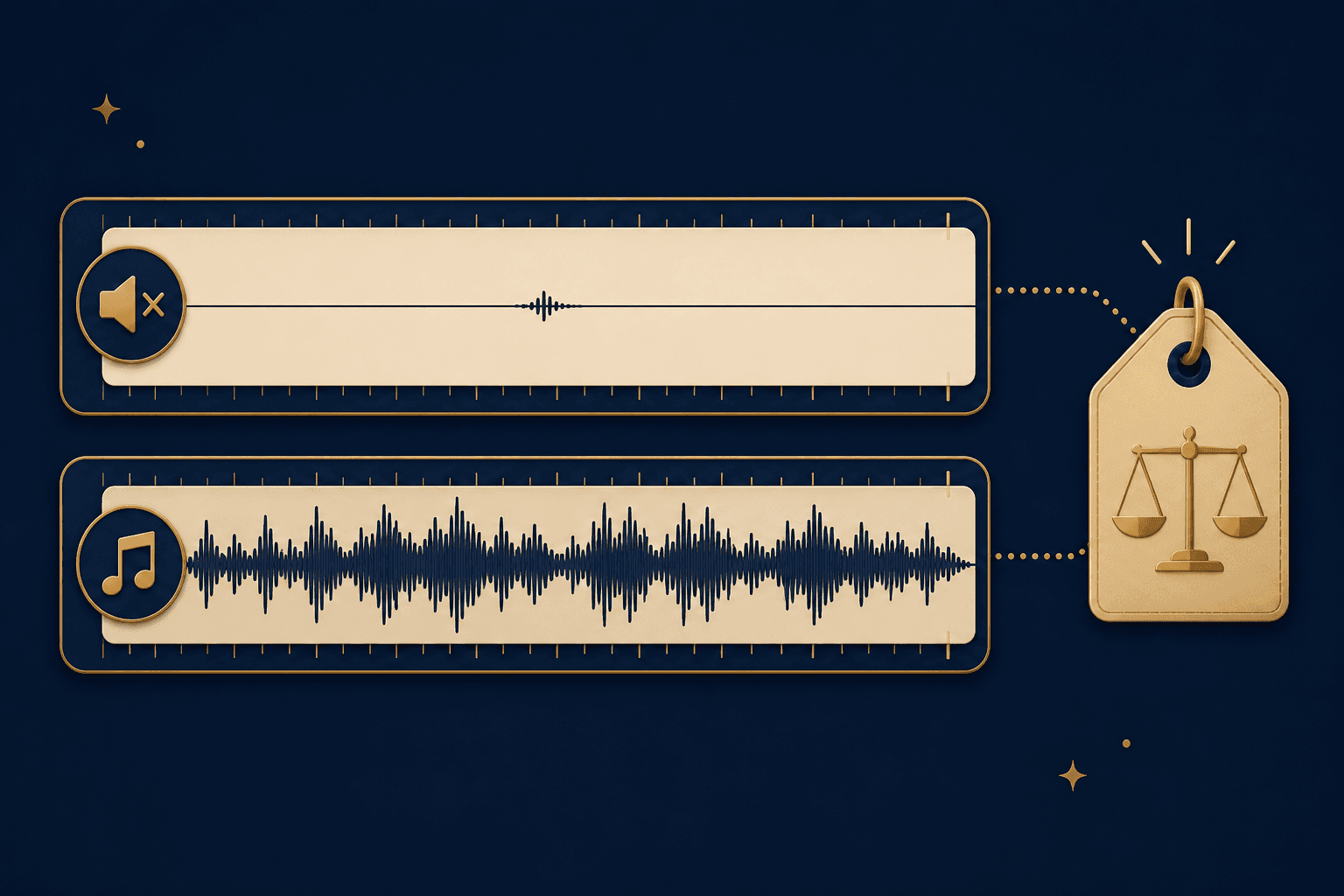
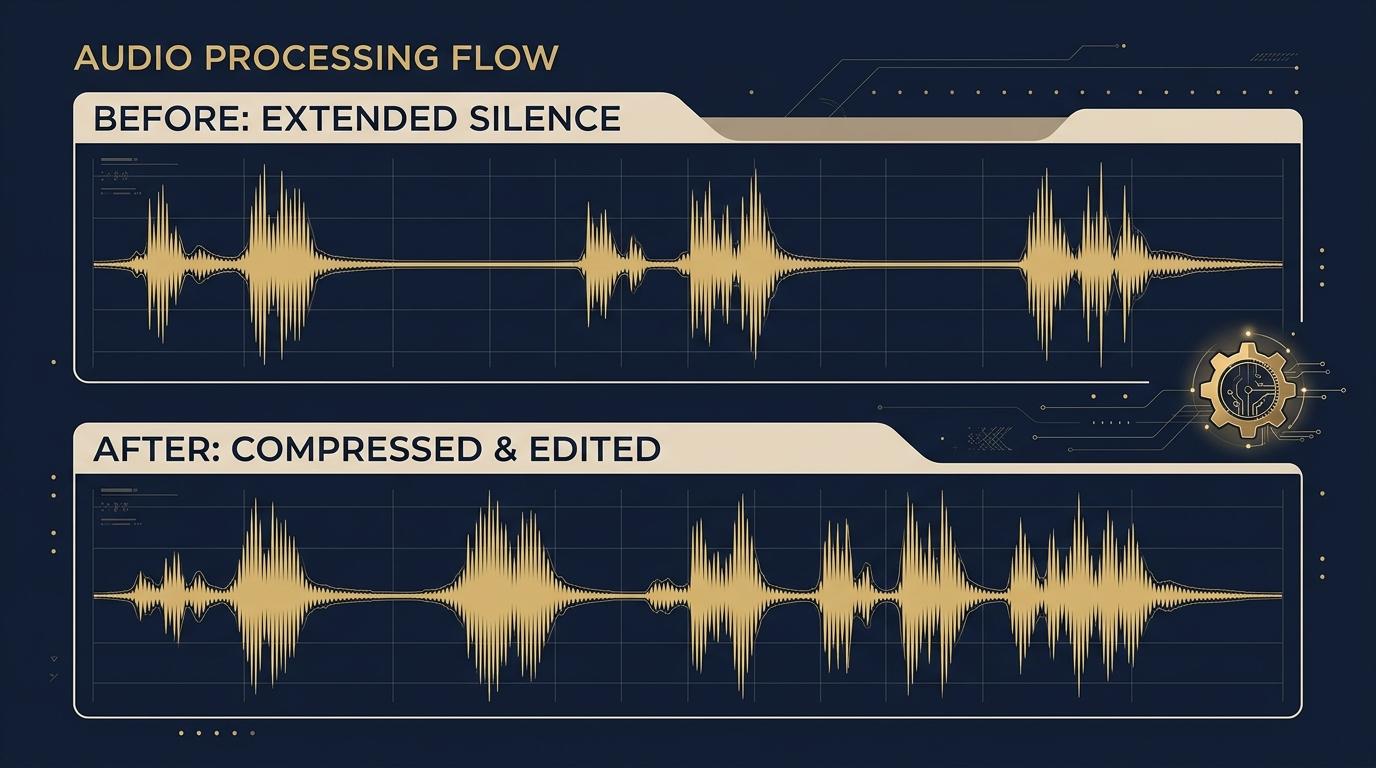
Twenty seconds of silence can cost the same as twenty seconds of dense audio. The fix: store the full recording, then strip dead air and speed up the clip before you send it to the model. Same insight for the LLM, lower bill.
Checklist
What to do on your next project
These are the rules worth adopting whether you are in the room at the meetup or reading this months later. Store sources. Separate derivatives. Version your runs. Shrink payloads at inference time, not at archive time.
Bring this list to your next system design review.
- ✓Store raw audio, video, logs, and notes
- ✓Keep processed derivatives in separate tables or paths
- ✓Version prompts and model IDs on every run
- ✓Compress pixels before API calls, not before storage
- ✓Trim silence and speed audio before billing, not before archive
Don't compress your intelligence
When you go back to building in Cursor this week: information loss is permanent. Capture the highest-fidelity data you can. Be ruthless about shrinking what you send to the API — never what you store for the future.
Explore more
Can Am Sales case study · Business process automation · How AI agents work